„Adatelemzés: bootstrap modellek” változatai közötti eltérés
| 4. sor: | 4. sor: | ||
ezt találtam: [http://en.wikipedia.org/wiki/Resampling_%28statistics%29] - Adrian | ezt találtam: [http://en.wikipedia.org/wiki/Resampling_%28statistics%29] - Adrian | ||
--> | --> | ||
| + | Egy ''X'' valószínűségi változó eloszlását különféle paraméterekkel jellemezhetjük: várható érték, szórás, ferdeség, stb. Ezeket a paramétereket egy ''n'' elemű minta alapján statisztikai függvények segítségével becsüljük. Pl.: a várható értéket a mintaátlaggal becsüljük, az empirikus és a korrigált empirikus szórás a szórás becslései. A becslésektől elvárjuk, hogy (legalább aszimptotikusan) torzítatlanok legyenek, valamint a becslés standard hibája a mintaszám növelésével nullához tartson. Ha kicsi a mintaszámunk, akkor nemcsak, hogy pontatlan lesz a becslésünk, de a pontosság jellemzőit sem tudjuk megbecsülni (pl.: konfidencia-intervallum) a klasszikus statisztika eszközeivel. | ||
| + | |||
| + | Mikor nevezhető kicsinek a mintaszám? Akkor, ha a becslés pontossági jellemzőinek (torzítás, standard hiba, konfidencia-intervallum) az ''n'' elemű mintából történő becslésekor indokolatlan a határeloszlásra való áttérés (a "klasszikus" képletek nem alkalmazhatók). A probléma megoldására találták ki az újra mintavételező módzsereket | ||
==Bootstrap módszer== | ==Bootstrap módszer== | ||
| + | Legyen ''X'' egy valószínűségi változó, <math>x = (x_1, x_2, ..., x_n)</math> pedig egy ''n'' elemű minta X-re, s(x) pedig ''X'' valamely paraméterének becslése. A bootstrap-szimuláció során visszatevéssel egy új, szintén ''n'' elemű mintát veszünk: <math>x^* = (x_1^*, x_2^*, ..., x_n^*)</math>. Pl.: n=5-re: <math>x^* = (x_2, x_4, x_1, x_2, x_1)\,</math>. Az x<sup>*</sup>-ra is alkalmazzuk s(x)-et, így s(x<sup>*</sup>)-ot kapjuk. Az eljárást N-szer megismételjük, így kapjuk s(x)-ek egy sorozatát: <math>s(x_1^*), s(x_2^*), ... s(x_N^*)</math>. Ha N elég nagy, akkor az s(x) becslés ''bootstrap-utánzatainak'' empirikus eloszlása jól modellezi az adott statisztika elméleti eloszlását. | ||
==Jackknife módszer== | ==Jackknife módszer== | ||
A lap 2011. június 11., 21:04-kori változata
Egy X valószínűségi változó eloszlását különféle paraméterekkel jellemezhetjük: várható érték, szórás, ferdeség, stb. Ezeket a paramétereket egy n elemű minta alapján statisztikai függvények segítségével becsüljük. Pl.: a várható értéket a mintaátlaggal becsüljük, az empirikus és a korrigált empirikus szórás a szórás becslései. A becslésektől elvárjuk, hogy (legalább aszimptotikusan) torzítatlanok legyenek, valamint a becslés standard hibája a mintaszám növelésével nullához tartson. Ha kicsi a mintaszámunk, akkor nemcsak, hogy pontatlan lesz a becslésünk, de a pontosság jellemzőit sem tudjuk megbecsülni (pl.: konfidencia-intervallum) a klasszikus statisztika eszközeivel.
Mikor nevezhető kicsinek a mintaszám? Akkor, ha a becslés pontossági jellemzőinek (torzítás, standard hiba, konfidencia-intervallum) az n elemű mintából történő becslésekor indokolatlan a határeloszlásra való áttérés (a "klasszikus" képletek nem alkalmazhatók). A probléma megoldására találták ki az újra mintavételező módzsereket
Bootstrap módszer
Legyen X egy valószínűségi változó, 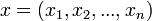 pedig egy n elemű minta X-re, s(x) pedig X valamely paraméterének becslése. A bootstrap-szimuláció során visszatevéssel egy új, szintén n elemű mintát veszünk:
pedig egy n elemű minta X-re, s(x) pedig X valamely paraméterének becslése. A bootstrap-szimuláció során visszatevéssel egy új, szintén n elemű mintát veszünk: 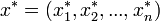 . Pl.: n=5-re:
. Pl.: n=5-re: 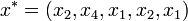 . Az x*-ra is alkalmazzuk s(x)-et, így s(x*)-ot kapjuk. Az eljárást N-szer megismételjük, így kapjuk s(x)-ek egy sorozatát:
. Az x*-ra is alkalmazzuk s(x)-et, így s(x*)-ot kapjuk. Az eljárást N-szer megismételjük, így kapjuk s(x)-ek egy sorozatát: 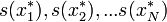 . Ha N elég nagy, akkor az s(x) becslés bootstrap-utánzatainak empirikus eloszlása jól modellezi az adott statisztika elméleti eloszlását.
. Ha N elég nagy, akkor az s(x) becslés bootstrap-utánzatainak empirikus eloszlása jól modellezi az adott statisztika elméleti eloszlását.